Modelos
SecureVu+ ofrece modelos entrenados con imágenes enviadas por usuarios de SecureVu+ desde sus cámaras de seguridad y está diseñado específicamente para la forma en que SecureVu VMS analiza las grabaciones de video. Estos modelos ofrecen mayor precisión con menos recursos. Las imágenes que cargas se usan para ajustar un modelo base entrenado con imágenes cargadas por todos los usuarios de SecureVu+. Este proceso de ajuste fino da como resultado un modelo optimizado para la precisión en tus condiciones específicas.
Con una suscripción, se incluyen 12 entrenamientos de modelos para ajustar tu modelo por año. Además, tendrás acceso a cualquier modelo base publicado mientras tu suscripción esté activa. Si cancelas tu suscripción, conservarás el acceso a cualquier modelo entrenado y base en tu cuenta. Se requiere una suscripción activa para enviar solicitudes de modelos o comprar entrenamientos adicionales. Los nuevos modelos base se publican trimestralmente con fechas objetivo del 15 de enero, 15 de abril, 15 de julio y 15 de octubre.
La información sobre cómo integrar SecureVu+ con SecureVu se puede encontrar en la documentación de integración.
Tipos de modelos disponibles
Hay tres tipos de modelos ofrecidos en SecureVu+: mobiledet, yolonas y yolov9. Todos estos modelos son modelos de detección de objetos y están entrenados para detectar el mismo conjunto de etiquetas listadas a continuación.
No todos los tipos de modelos son compatibles con todos los detectores, por lo que es importante elegir un tipo de modelo que coincida con tu detector como se muestra en la tabla bajo tipos de detectores compatibles. Puedes probar los tipos de modelos para compatibilidad y velocidad en tu hardware usando los modelos base.
| Tipo de Modelo | Descripción |
|---|---|
mobiledet | Basado en la misma arquitectura que el modelo predeterminado incluido con SecureVu. Se ejecuta en dispositivos Google Coral y CPU. |
yolonas | Una arquitectura más nueva que ofrece una precisión ligeramente mayor y una detección mejorada de objetos pequeños. Se ejecuta en GPU Intel, NVidia y AMD. |
yolov9 | Un modelo de detección de objetos SOTA (estado del arte) líder con rendimiento similar a yolonas, pero en una gama más amplia de opciones de hardware. Se ejecuta en la mayoría del hardware. |
Detalles de YOLOv9
Los modelos YOLOv9 están disponibles en variantes s, t, edgetpu. Al solicitar un modelo yolov9, se te pedirá que elijas una variante. Si deseas que el modelo sea compatible con un Google Coral, deberás elegir la variante edgetpu. Si no estás seguro de qué variante elegir, debes realizar algunas pruebas con los modelos base para encontrar el nivel de rendimiento que te convenga. El tamaño s es el más similar a los modelos actuales de yolonas en términos de tiempos de inferencia y precisión, y un buen punto de partida es el modelo de resolución 320x320 para yolov9s.
Al cambiar a YOLOv9, es posible que necesites ajustar tus umbrales para algunos objetos.
Soporte para Hailo
Si tienes un dispositivo Hailo, deberás especificar el hardware que tienes al enviar una solicitud de modelo porque no son compatibles entre sí. Por favor, prueba usando los modelos base disponibles antes de enviar tu solicitud de modelo.
Soporte para Rockchip (RKNN)
Los modelos Rockchip se convierten automáticamente a partir de la versión 0.17. Para la versión 0.16, los modelos YOLOv9 onnx deberán convertirse manualmente. Primero, deberás configurar SecureVu para usar el ID de modelo de tu modelo YOLOv9 onnx para que descargue el modelo en tu directorio model_cache. Desde allí, puedes seguir la documentación para convertirlo.
Tipos de detectores compatibles
Actualmente, los modelos de SecureVu+ admiten detectores CPU (cpu), Google Coral (edgetpu), OpenVino (openvino), ONNX (onnx), Hailo (hailo8l) y Rockchip (rknn).
| Hardware | Tipo de Detector Recomendado | Tipo de Modelo Recomendado |
|---|---|---|
| CPU | cpu | mobiledet |
| Coral (todos los factores de forma) | edgetpu | yolov9 |
| Intel | openvino | yolov9 |
| NVidia GPU | onnx | yolov9 |
| AMD ROCm GPU | onnx | yolov9 |
| Hailo8/Hailo8L/Hailo8R | hailo8l | yolov9 |
| Rockchip NPU | rknn | yolov9 |
Mejorar tu modelo
Algunos usuarios pueden encontrar que los modelos de SecureVu+ resultan en más falsos positivos inicialmente, pero al enviar verdaderos y falsos positivos, el modelo mejorará. Con todas las nuevas imágenes que están siendo enviadas por los suscriptores, los futuros modelos base mejorarán a medida que se incorporen más y más ejemplos. Ten en cuenta que solo las imágenes con al menos una etiqueta verificada se usarán al entrenar tu modelo. Enviar una imagen desde SecureVu como verdadero o falso positivo no verificará la imagen. Aún debes verificar la imagen en SecureVu+ para que se use en el entrenamiento.
- Envía tanto verdaderos positivos como falsos positivos. Esto ayudará al modelo a diferenciar entre lo que es correcto y lo que no. Debes apuntar a un objetivo del 80% de envíos de verdaderos positivos y 20% de falsos positivos en todas tus imágenes. Si experimentas falsos positivos en un área específica, enviar verdaderos positivos para cualquier tipo de objeto cerca de esa área en condiciones de iluminación similares ayudará a enseñar al modelo cómo se ve esa área cuando no hay objetos presentes.
- Baja tus umbrales un poco para generar más falsos/verdaderos positivos cerca del valor umbral. Por ejemplo, si tienes algunos falsos positivos con puntuaciones del 68% y algunos verdaderos positivos con puntuaciones del 72%, puedes intentar bajar tu umbral al 65% y enviar tanto verdaderos como falsos positivos dentro de ese rango. Esto ayudará al modelo a aprender y ampliar la brecha entre las puntuaciones de verdaderos y falsos positivos.
- Envía imágenes diversas. Para obtener los mejores resultados, debes proporcionar al menos 100 imágenes verificadas por cámara. Ten en cuenta que deben incluirse condiciones variadas. Querrás imágenes de días nublados, días soleados, amanecer, atardecer y noche. A medida que las circunstancias cambian, es posible que necesites enviar nuevos ejemplos para abordar nuevos tipos de falsos positivos. Por ejemplo, el cambio de días de verano a días de invierno con nieve u otros cambios como una nueva parrilla o muebles de patio pueden requerir ejemplos y entrenamiento adicionales.
Tipos de etiquetas disponibles
Los modelos de SecureVu+ admiten un conjunto de objetos más relevante para cámaras de seguridad. Las etiquetas para anotación en SecureVu+ son configurables editando la cámara en la sección Cámaras de SecureVu+. Actualmente, se admiten los siguientes objetos:
- Personas:
person,face - Vehículos:
car,motorcycle,bicycle,boat,school_bus,license_plate - Logotipos de Entrega:
amazon,usps,ups,fedex,dhl,an_post,purolator,postnl,nzpost,postnord,gls,dpd,canada_post,royal_mail - Animales:
dog,cat,deer,horse,bird,raccoon,fox,bear,cow,squirrel,goat,rabbit,skunk,kangaroo - Otros:
package,waste_bin,bbq_grill,robot_lawnmower,umbrella
Otros tipos de objetos disponibles en el modelo predeterminado de SecureVu no están disponibles. Se agregarán tipos de objetos adicionales en versiones futuras.
Etiquetas candidatas
Las etiquetas candidatas también están disponibles para anotación. Estas etiquetas aún no tienen suficientes datos para incluirse en el modelo, pero usarlas ayudará a agregar soporte más pronto. Puedes habilitar estas etiquetas editando la configuración de la cámara.
Cuando sea posible, estas etiquetas se mapean a etiquetas existentes durante el entrenamiento. Por ejemplo, cualquier etiqueta baby se mapea a person hasta que se agregue soporte para nuevas etiquetas.
Las etiquetas candidatas son: baby, bpost, badger, possum, rodent, chicken, groundhog, boar, hedgehog, tractor, golf cart, garbage truck, bus, sports ball, la_poste, lawnmower, heron, rickshaw, wombat, auspost, aramex, bobcat, mustelid, transoflex, airplane, drone, mountain_lion, crocodile, turkey, baby_stroller, monkey, coyote, porcupine, parcelforce, sheep, snake, helicopter, lizard, duck, hermes, cargus, fan_courier, sameday
Las etiquetas candidatas no están disponibles para sugerencias automáticas.
Atributos de etiquetas
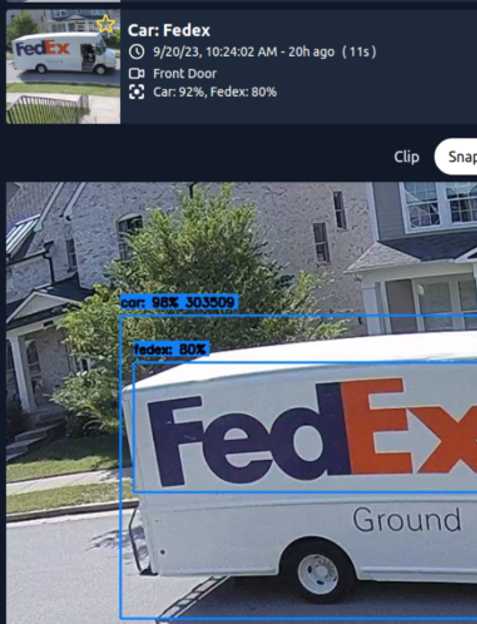
SecureVu tiene un manejo especial para algunas etiquetas cuando se usan modelos de SecureVu+. face, license_plate y los logotipos de entrega como amazon, ups y fedex se consideran etiquetas de atributos que no se rastrean como objetos regulares y no generan elementos de revisión directamente. Además, el filtro threshold no tendrá efecto en estas etiquetas. Debes ajustar el min_score y otros valores de filtro según sea necesario.
Para que SecureVu comience a usar estas etiquetas de atributos, deberás agregarlas a la lista de objetos a rastrear:
objects:
track:
- person
- face
- license_plate
- dog
- cat
- car
- amazon
- fedex
- ups
- package
Al usar modelos de SecureVu+, SecureVu elegirá la instantánea de un objeto de tipo persona que tenga el rostro más visible. Para los automóviles, se seleccionará la instantánea con la placa vehicular más visible. Esto ayuda en el procesamiento secundario como el reconocimiento facial y de placas vehiculares para objetos de tipo persona y automóvil.

Los logotipos de entrega como amazon, ups y fedex se usan para asignar automáticamente una sub etiqueta a los objetos de tipo automóvil.